Matthew Martinez
Former Research Associate
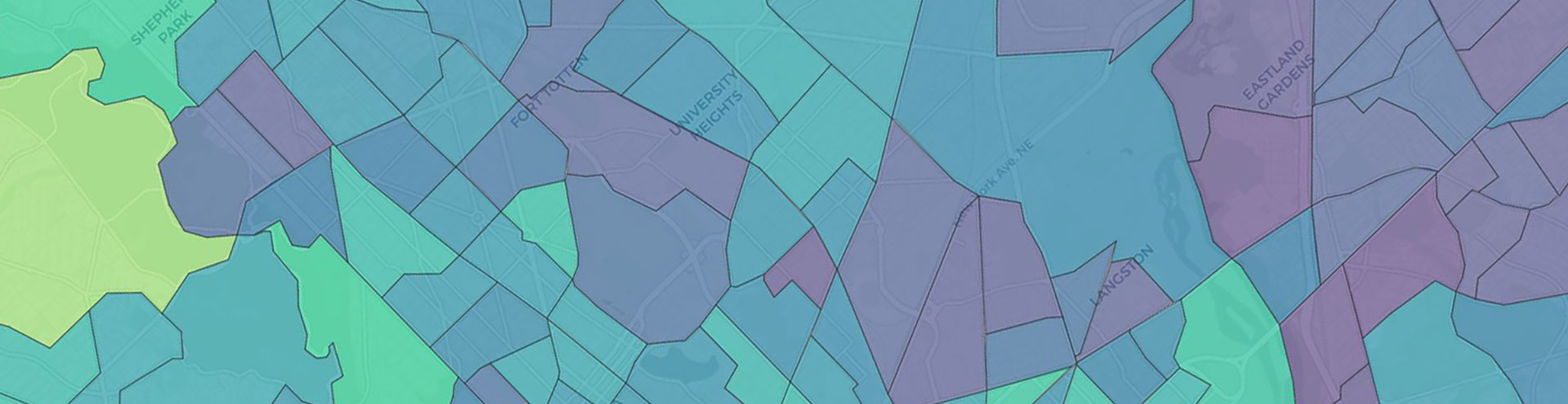
This map above has a customized hover-over message; when we hover over a tract, it displays relevant information. We can adjust the display to show specific data in a specific format. In addition, the map’s breakpoints and legend have been tailored to show income distribution by quartile.
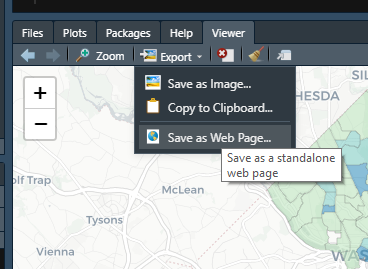
RStudio’s viewer makes it easy to save the interactive map as a HTML file. By clicking “Export,” we can access a dropdown menu and save the displayed map as a standalone HTML file, ready to be shared with others. It is as simple as uploading the file to a website and embedding it in a webpage or sending it to colleagues via email. No additional files or software are required.
R offers multiple paths for working with spatial data, far beyond the examples above. This tutorial only scratches the surface of R’s capabilities, which are extensive and constantly evolving through user contributions. To learn more about the basics of R, check out the free R for Data Science book. Or, for a thorough introduction to spatial data analysis and visualization using R, read the free Spatial Data Science book. With these tools, you’ll be developing your own maps in no time.
Annotated code for obtaining, processing, and visualizing the data for these examples can be found here.